An R-way trie is a tree where each node has \(R\) children. It’s best described by an example:
Each node consists only of two quantities: A vector of \(R\) entries, and a value (e.g. integer).
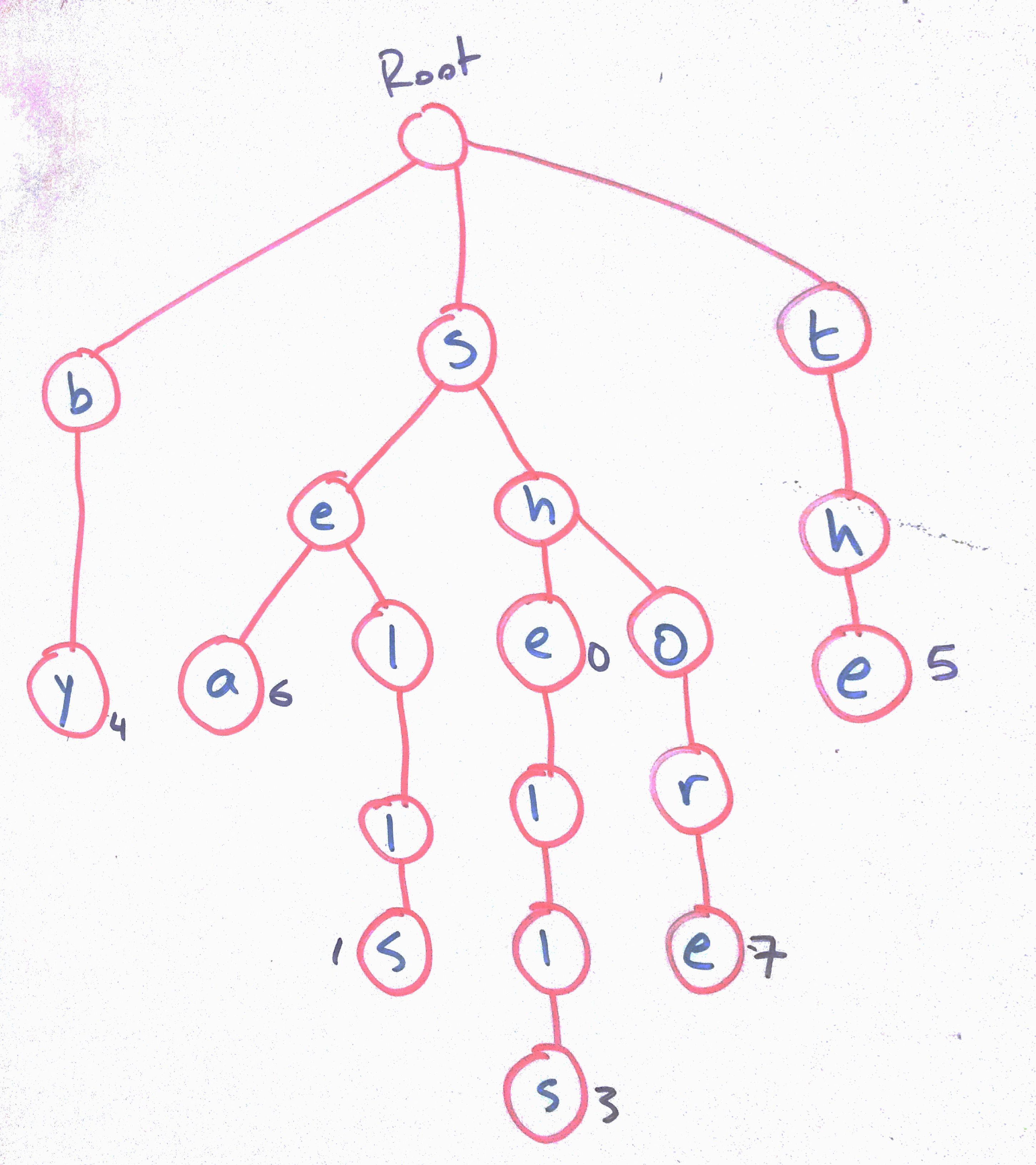
The root is “empty”. The 2nd element of its vector is non-null, which indicates the letter b. Likewise for s and t.
The following words have been stored in the trie:
by, sea, sells, shells, she, shore, the
Whenever a word ends, we place a value in the node to indicate the end of a word.
Question: Why a value and not just a boolean?
Note the compactness: If we have she and shells, we only need to store the extra characters l,l,s. So it’s a useful data structure for looking for common prefixes.
To insert a word, simply follow the prefix and create new nodes as needed. At the end, assign a value to the last character to indicate an end of word.
To delete a word, start from the last character and recursively delete until you encounter a character with a value. Also, if the last character had children, do not delete the node - simply delete the value in that node. So for example, to delete shells, you’d delete s, l, and l. But to delete she, simply remove the value from e.
Properties
- It is generally faster than hashing, as it takes sublinear time to find a miss.
- Due to the empty links in each node, it is wasteful. Each node has \(R\) links. If \(R\) is huge (e.g. Unicode), this is prohibitive.
Ternary Tries
Ternary tries are a modification of \(R\) tries. Each node has only three children. The middle child will have a character. The left and right children will simply have a character smaller/larger. So let’s say the first word is shell. The root node has s in it, its center node has h, its center node has e, etc. Then the next word is and. We insert a as the left child of s, and then its center node is n, and so on. If the next word is ball, we insert b in the right child of a, etc. If the next word is sells, we have already inserted shells. So we insert e to the left of h (and not the left of s). If we now want to insert sea, we have to insert a to the left of the l from sells.
This eliminates the problem of wasted space of an \(R\) trie. And it is typically faster.
Even faster is a hybrid of the two, where the root node is that of an \(R\) trie, and each of its links is a ternary trie. This way you get quick look up for the first character. Some go further and make the first two nodes those of \(R\) tries. Taking an example from English, there are 26 characters. With the two nodes, we have instant access to two letter prefixes. This uses up space of \(26^{2}\), but it may be worth it.
With ternary tries, balancing is a concern. If you insert a sorted list, you’ll get a heavily unbalanced trie.